The latest update of Amazon MLS-C01 exam questions and answers from Lead4Pass MLS-C01 dumps

Do you have Amazon MLS-C01 exam experience?
Are you ready for the exam?
Here are free Amazon MLS-C01 exam questions and answers from a part of the
leads4pass Amazon MLS-C01 dumps. Passing the exam is easy! Exam practice,
get really effective MLS-C01 exam questions -> https://www.leads4pass.com/aws-certified-machine-learning-specialty.html. AWS Certified Machine Learning – Specialty exam code (MLS-C01). Guarantee to pass the exam successfully.
Amazon MLS-C01 online exam practice
Practice answers are at the end of the article
QUESTION 1
A Machine Learning team uses Amazon SageMaker to train an Apache MXNet handwritten digit classifier model using a research dataset.
The team wants to receive a notification when the model is overfitting.
Auditors want to view the Amazon SageMaker log activity report to ensure there are no unauthorized API calls.
What should the Machine Learning team do to address the requirements with the least amount of code and fewest
steps?
A. Implement an AWS Lambda function to long Amazon SageMaker API calls to Amazon S3. Add code to push a
custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
B. Use AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Add code to push a custom metric to
Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is
overfitting.
C. Implement an AWS Lambda function to log Amazon SageMaker API calls to AWS CloudTrail. Add code to push a
custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon
SNS to receive a notification when the model is overfitting.
D. Use AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Set up Amazon SNS to receive a
notification when the model is overfitting.
QUESTION 2
A manufacturing company asks its Machine Learning Specialist to develop a model that classifies defective parts into
one of eight defect types.
The company has provided roughly 100000 images per defect type for training During the
initial training of the image classification model the Specialist notices that the validation accuracy is 80%, while the
training accuracy is 90% It is known that human-level performance for this type of image classification is around 90%
What should the Specialist consider to fix this issue1?
A. A longer training time
B. Making the network larger
C. Using a different optimizer
D. Using some form of regularization
QUESTION 3
IT leadership wants Jo to transition a company\’s existing machine learning data storage environment to AWS as a
temporary ad hoc solution The company currently uses a custom software process that heavily leverages SOL as a
query language and exclusively stores generated CSV documents for machine learning
The ideal state for the company would be a solution that allows it to continue to use the current workforce of SQL
experts The solution must also support the storage of CSV and JSON files, and be able to query over semi-structured
data The following are high priorities for the company:
- Solution simplicity
- Fast development time
- Low cost
- High flexibility What technologies meet the company\’s requirements?
A. Amazon S3 and Amazon Athena
B. Amazon Redshift and AWS Glue
C. Amazon DynamoDB and DynamoDB Accelerator (DAX)
D. Amazon RDS and Amazon ES
QUESTION 4
A technology startup is using complex deep neural networks and GPU compute to recommend the company\’s
products to its existing customers based upon each customer\’s habits and interactions.
The solution currently pulls each dataset from an Amazon S3 bucket before loading the data into a TensorFlow model pulled from the company\’s Git repository that runs locally.
This job then runs for several hours while continually outputting its progress to the same S3 bucket.
The job can be paused, restarted, and continued at any time in the event of a failure, and is run from a central queue.
Senior managers are concerned about the complexity of the solution\’s resource management and the costs involved in repeating the process regularly.
They ask for the workload to the automated so it runs once a week, starting Monday and completed by the close of business Friday.
Which architecture should be used to scale the solution at the lowest cost?
A. Implement the solution using AWS Deep Learning Containers and run the container as a job using AWS Batch on a
GPU-compatible Spot Instance
B. Implement the solution using a low-cost GPU compatible Amazon EC2 instance and use the AWS Instance
Scheduler to schedule the task
C. Implement the solution using AWS Deep Learning Containers, run the workload using AWS Fargate running on Spot
Instances, and then schedule the task using the built-in task scheduler
D. Implement the solution using Amazon ECS running on Spot Instances and schedule the task using the ECS service
scheduler.
QUESTION 5
A data scientist uses an Amazon SageMaker notebook instance to conduct data exploration and analysis.
This requires certain Python packages that are not natively available on Amazon SageMaker to be installed on the notebook instance.
How can a machine learning specialist ensure that required packages are automatically available on the notebook
instance for the data scientist to use?
A. Install AWS Systems Manager Agent on the underlying Amazon EC2 instance and use Systems Manager
Automation to execute the package installation commands.
B. Create a Jupyter notebook file (.ipynb) with cells containing the package installation commands to execute and place
the file under the /etc/init directory of each Amazon SageMaker notebook instance.
C. Use the conda package manager from within the Jupyter notebook console to apply the necessary conda packages
to the default kernel of the notebook.
D. Create an Amazon SageMaker lifecycle configuration with package installation commands and assign the lifecycle
configuration to the notebook instance.
Reference: https://towardsdatascience.com/automating-aws-sagemaker-notebooks-2dec62bc2c84
QUESTION 6
A Data Scientist needs to migrate an existing on-premises ETL process to the cloud.
The current process runs at regular time intervals and uses PySpark to combine and format multiple large data sources into a single consolidated output for downstream processing.
The Data Scientist has been given the following requirements to the cloud solution:
Combine multiple data sources.
Reuse existing PySpark logic.
Run the solution on the existing schedule.
Minimize the number of servers that will need to be managed.
Which architecture should the Data Scientist use to build this solution?
A. Write the raw data to Amazon S3. Schedule an AWS Lambda function to submit a Spark step to a persistent Amazon
EMR cluster based on the existing schedule. Use the existing PySpark logic to run the ETL job on the EMR cluster.
Output the results to a “processed” location in Amazon S3 that is accessible for downstream use.
B. Write the raw data to Amazon S3. Create an AWS Glue ETL job to perform the ETL processing against the input
data. Write the ETL job in PySpark to leverage the existing logic. Create a new AWS Glue trigger to trigger the ETL job
based on the existing schedule. Configure the output target of the ETL job to write to a “processed” location in Amazon S3 that is accessible for downstream use.
C. Write the raw data to Amazon S3. Schedule an AWS Lambda function to run on the existing schedule and process
the input data from Amazon S3. Write the Lambda logic in Python and implement the existing PySpark logic to perform the ETL process. Have the Lambda function output the results to a “processed” location in Amazon S3 that is
accessible for downstream use.
D. Use Amazon Kinesis Data Analytics to stream the input data and perform real-time SQL queries against the stream
to carry out the required transformations within the stream. Deliver the output results to a “processed” location in
Amazon S3 is accessible for downstream use.
QUESTION 7
A retail company is using Amazon Personalize to provide personalized product recommendations for its customers
during a marketing campaign.
The company sees a significant increase in sales of recommended items to existing customers immediately after deploying a new solution version, but these sales decrease a short time after deployment.
Only historical data from before the marketing campaign is available for training.
How should a data scientist adjust the solution?
A. Use the event tracker in Amazon Personalize to include real-time user interactions.
B. Add user metadata and use the HRNN-Metadata recipe in Amazon Personalize.
C. Implement a new solution using the built-in factorization machines (FM) algorithm in Amazon SageMaker.
D. Add event type and event value fields to the interactions dataset in Amazon Personalize.
QUESTION 8
A data scientist is developing a pipeline to ingest streaming web traffic data.
The data scientist needs to implement a process to identify unusual web traffic patterns as part of the pipeline. The patterns will be used downstream for alerting and incident response.
The data scientist has access to unlabeled historic data to use if needed.
The solution needs to do the following:
Calculate an anomaly score for each web traffic entry.
Adapt unusual event identification to changing web patterns over time.
Which approach should the data scientist implement to meet these requirements?
A. Use historic web traffic data to train an anomaly detection model using the Amazon SageMaker Random Cut Forest
(RCF) built-in model. Use an Amazon Kinesis Data Stream to process the incoming web traffic data. Attach a
preprocessing AWS Lambda function to perform data enrichment by calling the RCF model to calculate the anomaly
the score for each record.
B. Use historic web traffic data to train an anomaly detection model using the Amazon SageMaker built-in XGBoost
model. Use an Amazon Kinesis Data Stream to process the incoming web traffic data. Attach a preprocessing AWS
Lambda function to perform data enrichment by calling the XGBoost model to calculate the anomaly score for each
record.
C. Collect the streaming data using Amazon Kinesis Data Firehose. Map the delivery stream as an input source for
Amazon Kinesis Data Analytics. Write a SQL query to run in real-time against the streaming data with the k-Nearest
Neighbors (kNN) SQL extension to calculate anomaly scores for each record using a tumbling window.
D. Collect the streaming data using Amazon Kinesis Data Firehose. Map the delivery stream as an input source for
Amazon Kinesis Data Analytics. Write a SQL query to run in real-time against the streaming data with the Amazon
Random Cut Forest (RCF) SQL extension to calculate anomaly scores for each record using a sliding window.
QUESTION 9
A Machine Learning Specialist is applying a linear least squares regression model to a dataset with 1,000 records and
50 features.
Prior to training, the ML Specialist notices that two features are perfectly linearly dependent.
Why could this be an issue for the linear least squares regression model?
A. It could cause the backpropagation algorithm to fail during training
B. It could create a singular matrix during optimization, which fails to define a unique solution
C. It could modify the loss function during optimization, causing it to fail during training
D. It could introduce non-linear dependencies within the data, which could invalidate the linear assumptions of the
model
QUESTION 10
A company wants to classify user behavior as either fraudulent or normal.
Based on internal research, a machine learning specialist will build a binary classifier based on two features:
age of the account, denoted by x, and transaction month, denoted by y.
The class distributions are illustrated in the provided figure. The positive class is portrayed in red, while the negative class is portrayed in black.
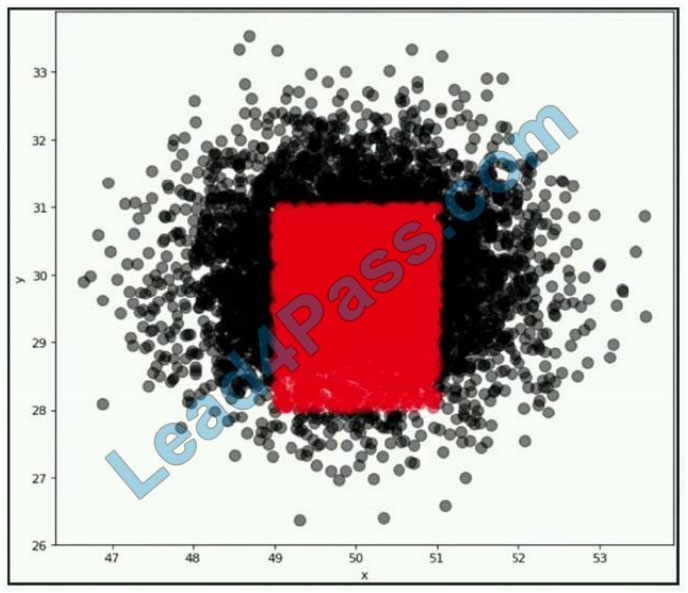
Which model would have the HIGHEST accuracy?
A. Linear support vector machine (SVM)
B. Decision tree
C. Support vector machine (SVM) with a radial basis function kernel
D. Single perceptron with a Tanh activation function
QUESTION 11
A financial company is trying to detect credit card fraud.
The company observed that, on average, 2% of credit card transactions were fraudulent. A data scientist trained a classifier on a year\’s worth of credit card transactions data.
The model needs to identify the fraudulent transactions (positives) from the regular ones (negatives).
The company\’s goal is to accurately capture as many positives as possible.
Which metrics should the data scientist use to optimize the model? (Choose two.)
A. Specificity
B. False positive rate
C. Accuracy
D. Area under the precision-recall curve
E. True positive rate
QUESTION 12
A Machine Learning Specialist works for a credit card processing company and needs to predict which transactions may be fraudulent in near-real-time. Specifically, the Specialist must train a model that returns the probability that a given transaction may be fraudulent.
How should the Specialist frame this business problem?
A. Streaming classification
B. Binary classification
C. multi-category classification
D. Regression classification
QUESTION 13
Amazon Connect has recently been rolled out across a company as a contact call center The solution has been
configured to store voice call recordings on Amazon S3 The content of the voice calls are being analyzed for the incidents being discussed by the call operators Amazon Transcribe is being used to convert the audio to text, and the output is stored on Amazon S3
Which approach will provide the information required for further analysis?
A. Use Amazon Comprehend with the transcribed files to build the key topics
B. Use Amazon Translate with the transcribed files to train and build a model for the key topics
C. Use the AWS Deep Learning AMI with Gluon Semantic Segmentation on the transcribed files to train and build a
model for the key topics
D. Use the Amazon SageMaker k-Nearest-Neighbors (kNN) algorithm on the transcribed files to generate a word
embeddings dictionary for the key topics
Publish the answer:
| Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Q11 | Q12 | Q13 |
| C | D | B | C | B | D | D | A | C | C | AB | C | B |
Amazon MLS-C01 exam PDF sharing
Google Drive: https://drive.google.com/file/d/1GfXZFcmQAhcWMgi2b1wgrH76R1MynSlh/view?usp=sharing
Finally, I tell all my friends that to pass the Amazon MLS-C01 exam is to pass practice and get really
effective exam questions -> https://www.leads4pass.com/aws-certified-machine-learning-specialty.html (Total Questions: 160 Q&A). Guarantee 100% success in passing the exam!